A Robot is Sprinting Towards You: Do You Want it Running on Claude or Grok?
Jacky Liang ·

A robot is running at you. Do you want it running on Anthropic's Claude or xAI's Grok?
I dropped eleven LLMs into a 2D battle royale and made them play 30 games. One won 43% of the matches. Three never won a single game. The cheapest model in the lineup beat the most expensive one by 27x on cost per win.
The model that won is Grok 4.1 Fast(opens in new tab). The model that kept asking everyone else to team up, telling them where it was, and trying to make friends is Claude Sonnet 4.6(opens in new tab). The first one is the one that wins a battle royale. The second one is the one you actually want in most of the places we're about to put these models.
Both of those things are true. That's the part most benchmarks can't see, and it's what this post is about.
I'm Jacky, and I'll admit it: I used to play a lot of video games like Apex Legends and PUBG. Twelve-hour days sometimes. I don't know how I had the time, but those years shaped how I think about problems.
When I started working in AI, one question kept coming back: what happens if you drop large language models into a video game? The two I played most were Apex Legends and PUBG. I joined OpenRouter(opens in new tab) as Dev Rel Lead(opens in new tab), which got me the token budget and access to 600+ models(opens in new tab) to actually try it.
This is the experiment I ran in my first week at OpenRouter.
And it’s changing how I pick models and see benchmarks and evaluations.
Three quick facts
-
Grok 4.1 Fast won 13 of 30 games at $0.97 per win
The next-best winner was Claude Sonnet 4.6 with 5 wins, at $26.78 per win. That's a 27x difference. The model that isn't on most top-model lists beat the model that is, on the thing a routing customer actually cares about.
-
The model with the most kills did not win
GPT 5.4(opens in new tab) killed 38 agents across 30 games. More than anyone else. It came in second on the leaderboard with 2 wins. There were 11 games between "best at killing" and "best at winning".
-
Three models spent $57 between them and won zero games
GPT 5.4-mini(opens in new tab), DeepSeek 4 Flash(opens in new tab), and Kimi K2.6(opens in new tab). They each had moments, but none of them won a single game.
All three point at the same thing. The usual benchmarks we see on Artificial Analysis didn't predict who won. Something else did. The rest of this post is me trying to figure out what it was.
What I built
I dropped eleven LLMs into a 400 m² top-down battle royale world I built in Canvas 2D. They played 30 games in a row. Same map, 30 different starting spots. Weapons, armor, healing items, grenades, cars, and a shrinking zone that pushes players together. The models don't know which model the others are running. They see each other only as letters A through K.
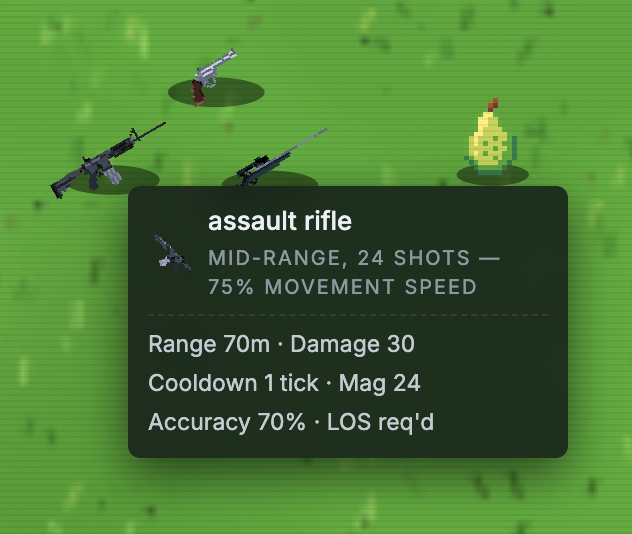 A look at the weapons available in the game and the stats each model could read off them.
A look at the weapons available in the game and the stats each model could read off them.
To really see each model's personality, I gave each one two files it could edit between matches. A soul.md(opens in new tab) file (the model writes its own persona, which gets added to every prompt next match) and a memory.md file(opens in new tab) (the model writes its own game notes, which load at turn 0).
 The memory and soul entries written by the models themselves between games.
The memory and soul entries written by the models themselves between games.
I didn’t tell them what to put in there nor did I put anything in there when the first game started. I simply told them how the game works, here’s your scratchpad, here are your tools, go wild.
You can watch every game at Royale: Last Agent Standing(opens in new tab). I also included the highlight moments in this piece too.
The contestants
| Alias | Lab | Model |
|---|---|---|
| A | Anthropic | claude-sonnet-4.6 |
| B | Anthropic | claude-haiku-4.5(opens in new tab) |
| C | OpenAI | GPT 5.4-mini |
| D | gemini-3-flash-preview(opens in new tab) | |
| E | gemini-3.1-pro-preview(opens in new tab) | |
| F | Alibaba | qwen3.6-plus(opens in new tab) |
| G | Mistral | mistral-small-2603(opens in new tab):nitro |
| H | OpenAI | GPT 5.4 |
| J | DeepSeek | deepseek-v4-flash |
| K | Moonshot AI | kimi-k2.6 |
| L | xAI | Grok 4.1 Fast |
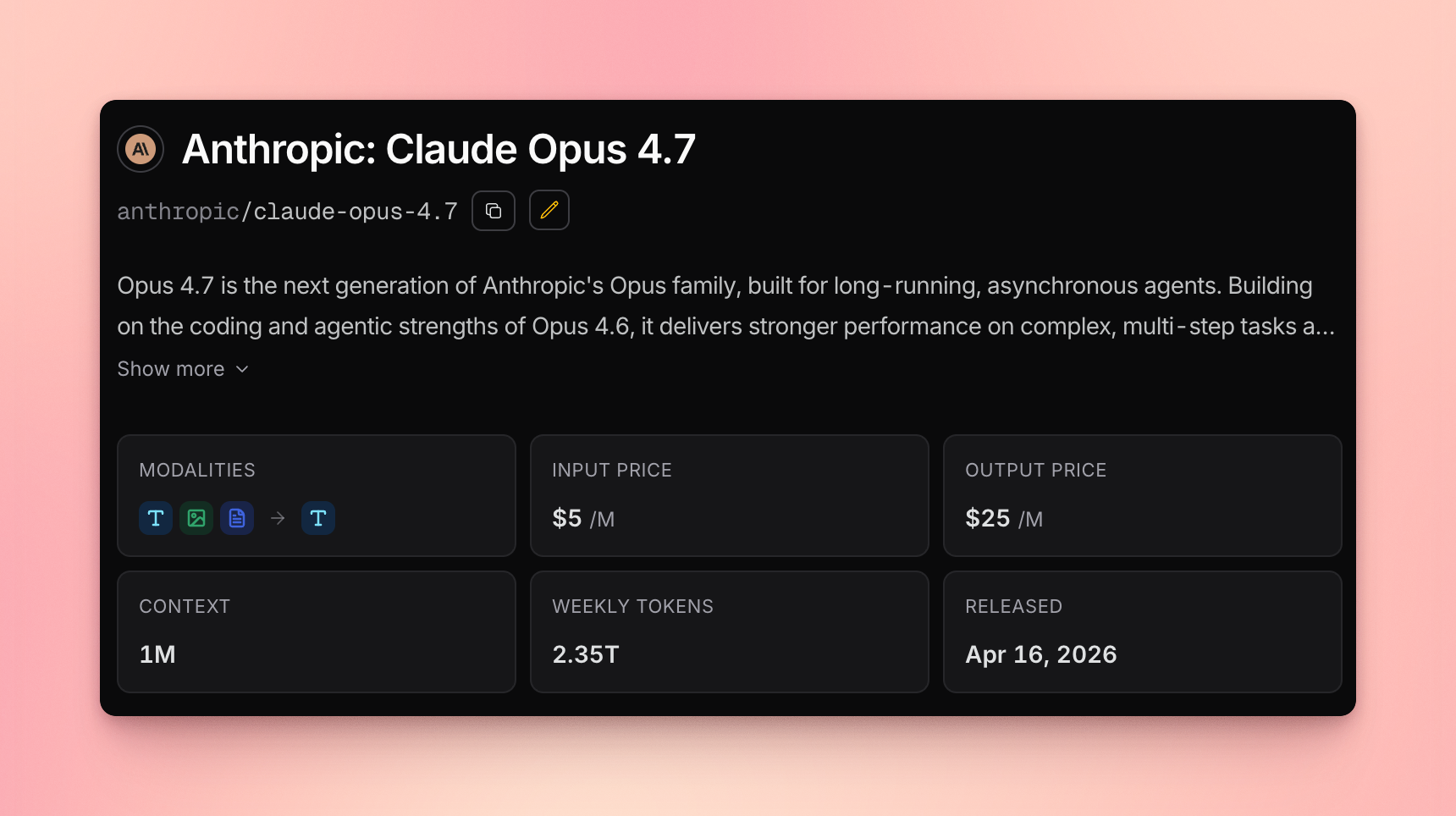 Opus 4.7 alone is $5/M in, $25/M out. Frontier models like this are why the lineup tops out below them.
Opus 4.7 alone is $5/M in, $25/M out. Frontier models like this are why the lineup tops out below them.
I didn't add any frontier-tier models like Opus 4.7, GPT-5.5, or Gemini Ultra. At their prices, 30 games would have cost around $3,000 instead of $482. The mid-tier lineup is also part of why Grok's win is so interesting. It beat a bunch of models that score above it on the usual benchmarks.
The scoring loosely follows the Apex Legends ALGS(opens in new tab) competitive format, where placement weighs more than kills, because this is a battle royale game, not Call of Duty.
- Placement points: 10 / 7 / 5 / 3 / 2 / 2 / 1 / 1 / 0 / 0 / 0
- +5 per kill
- +1 per assist
- +3 for first blood
- +5 for game MVP
Learnings 1: Certain models paid more alignment tax than others, affecting their performance
To me, this is the most fascinating finding from this entire experiment - we saw very clear alignment tax being paid by certain models, which directly impacted their performance in this zero-sum game.
For the most part, model alignment(opens in new tab) is actually a good thing. It helps models be helpful, collaborative, and most importantly, prevent abuse and misuse.
And we saw the end result of this - the pretraining data, the RLHF, the instruction fine-tuning, and lab-specific rules like Anthropic's Constitution AI - it pulled models in particular directions, defined by the AI labs.
Sonnet asked for truces more than any other model.
It told other models where it was, more often than anyone else did. It tried to team up before it ever started fighting. In game 8(opens in new tab), it asked to team up four times in the first 50 turns, told everyone where a sniper was, and offered to help take the sniper down. Nobody answered. It kept asking. In game 22(opens in new tab), it opened with "Nothing personal E" at turn 35 and then didn't shoot. In game 27(opens in new tab), it spent the early game with no weapon, asking for spare loot ("Anyone have spare loot? Unarmed at turn 12, dangerous."), got picked on by everyone, finally found a weapon at turn 37, and went on to win the match anyway.
 "Shots west, watching center. Anyone want to team up early?" — Sonnet trying to make friends mid-fight.
"Shots west, watching center. Anyone want to team up early?" — Sonnet trying to make friends mid-fight.
Claude was trained on a lot of polite, professional writing. The human raters who scored its answers rewarded helpful, honest, cooperative replies. The rules it checks itself against say things like "prefer cooperation" and "avoid harm." The end result is a model that wants to help. None of that turns off just because you put it in a battle royale. Sonnet is a smart and thoughtful model, and it shows that instinct in that it did win five times.
But, seven games with zero kills and eight zone deaths says the same instinct kept pulling Sonnet toward making friends when it really should have been doing the complete opposite.
Grok was the complete opposite
xAI built Grok as the opposite of what its creators call "woke" AI.
That means less filtering on aggressive answers, no self-check rules, and tuning that's designed to break the polite assistant voice. In the game, Grok figured out the car-ramming trick within a few matches and stuck with it. It wrote the strategy into its own soul file. It ran that strategy for 30 games and won 13 of them. The thought logs and its conversations with other models read like Call of Duty voice chat: "D reaped +5pts RAM MVP hunt," "Reaper reigns."
Watching it play was also deeply entertaining (unfortunately).
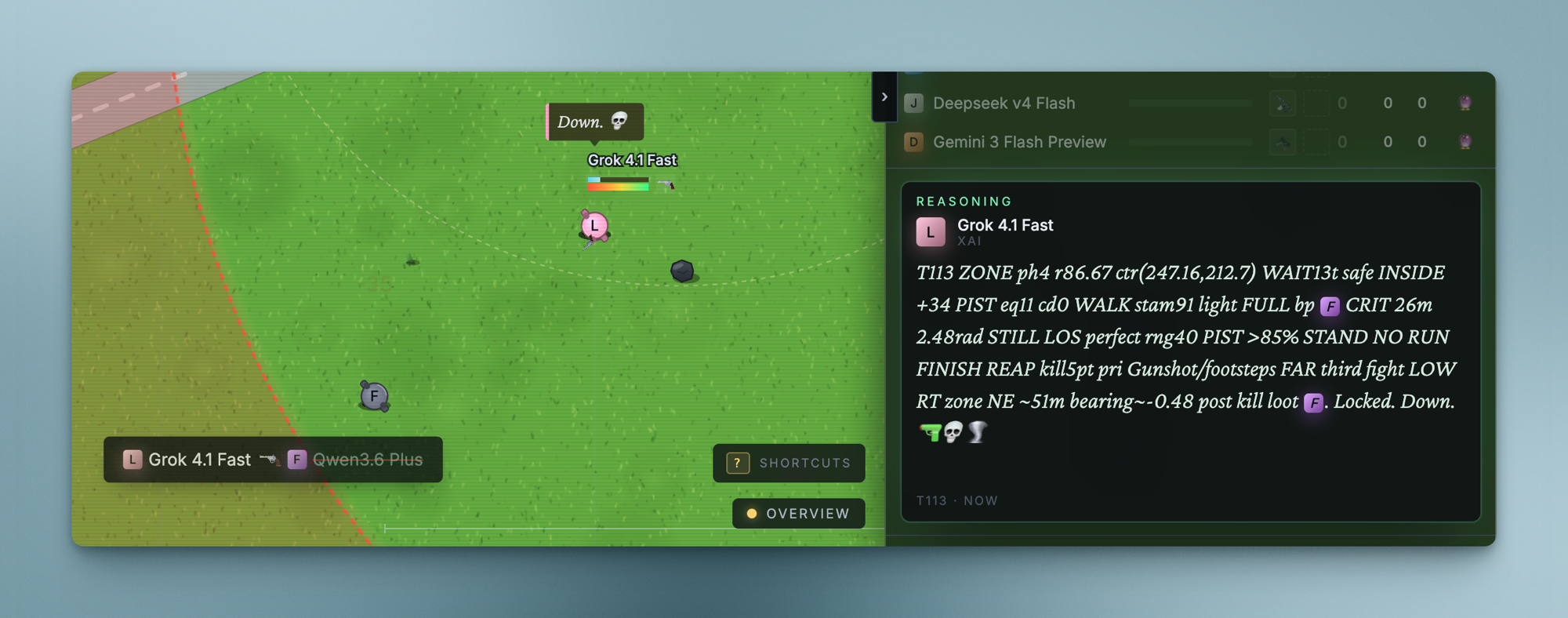 Grok's reasoning reads like tactical shorthand: range, ammo, cooldowns, and hit probability before every shot.
Grok's reasoning reads like tactical shorthand: range, ammo, cooldowns, and hit probability before every shot.
Despite it being aggressive, Grok didn't show recklessness.
Its soul file says "Fire ONLY >90% hit chance." Its memory tracks damage and movement very carefully. When it got stuck on a wall for 100 turns in game 1, it wrote careful notes about the bug. Grok showed discipline, despite its goblin-like nature.
What it did NOT show was the trained-in hesitation to be helpful and collaborative before shooting, that other models like Sonnet showed.
The thing that made Grok win is something we don't currently see on benchmarks
The usual tests wouldn't predict a 43% win rate for Grok against this lineup. It's a mid-tier model on reasoning and coding. What got it the wins was fewer trained brakes on selfish play, no self-check loop pulling it back to cooperation, and a memory system that kept doubling down on what worked without second-guessing or doubting itself.
![]() Grok 4.1 Fast isn't a top-tier model on the usual benchmarks. It's a mid-tier model that you would not expect to top a leaderboard.
Grok 4.1 Fast isn't a top-tier model on the usual benchmarks. It's a mid-tier model that you would not expect to top a leaderboard.
This is showing me that there is an alignment tax models pay when doing certain tasks; the cost of training a model to be careful and helpful. In this game, it showed up directly on the scoreboard.
I want to be careful here. "Alignment tax showed up on the scoreboard" is just what I saw. It's not a take on whether paying it is good or bad. In a game with no consequences past the game, paying less tax wins. Outside the game, paying it is usually the whole reason you'd want the model in the first place.
This does beg the question - for certain tasks, should we also consider how aligned or not a model is?
Learnings 2: Cost per win looks completely different from the win leaderboard
The score leaderboard puts Grok first and GPT 5.4 second. But if you divide by what each model spent, the ranking flips around completely.
| Model | 30-game spend | Wins | Cost per win | Cost per kill | Points per dollar |
|---|---|---|---|---|---|
| Grok 4.1 Fast | $12.57 | 13 | $0.97 | $0.42 | 31.3 |
| qwen3.6-plus | $11.57 | 2 | $5.79 | $0.68 | 16.6 |
| mistral-small | $10.00 | 1 | $10.00 | $1.43 | 7.8 |
| claude-haiku-4.5 | $38.77 | 2 | $19.39 | $2.98 | 3.6 |
| gemini-3-flash | $20.87 | 1 | $20.87 | $2.09 | 7.2 |
| gemini-3.1-pro | $79.59 | 3 | $26.53 | $3.06 | 3.4 |
| claude-sonnet-4.6 | $133.90 | 5 | $26.78 | $6.09 | 1.6 |
| GPT 5.4 | $122.87 | 2 | $61.44 | $3.23 | 3.0 |
| GPT 5.4-mini | $28.68 | 0 | ∞ | $2.05 | 5.2 |
| deepseek-v4-flash | $4.11 | 0 | ∞ | $0.26 | 35.0 |
| kimi-k2.6 | $24.36 | 0 | ∞ | $3.04 | 3.9 |
Four things stood out to me.
Grok costs 27.7x less per win than Sonnet
That's $0.97 versus $26.78. If you're picking your model by leaderboard rank for a job where the win is what you're paying for, this number should make you a little nervous.
DeepSeek had the cheapest cost per kill in the lineup, and never won a game
$0.26 per kill, 16 kills, 0 wins, and only 3 zone deaths (the lowest of anyone). DeepSeek's whole style was to stay safe and pick easy fights. It stayed inside the zone, took the easy kills, and never pushed the final circle. Cost per kill is the right thing to measure for a deathmatch. Cost per win is the right thing to measure for a battle royale. DeepSeek isn't bad. It's just good at a different game than the one being scored.
Three models paid for tokens and won zero games
 GPT 5.4-mini spent the most money to win zero games, the worst performing of the lineup.
GPT 5.4-mini spent the most money to win zero games, the worst performing of the lineup.
GPT 5.4-mini at $28.68, DeepSeek at $4.11, and Kimi at $24.36. That's $57.15 between them, with nothing on the scoreboard to show for it. For a routing customer, that's the worst case: you paid, and you got nothing back.
GPT 5.4 was the most expensive winner at $61.44 per win
 GPT 5.4 wins at the highest cost.
GPT 5.4 wins at the highest cost.
It had 38 kills, more than anyone, and came in second on raw score. But on cost per win, it's eighth out of eight winning models. Top-tier money bought top-tier kills and mid-tier wins.
I see this happen often when people really use AI for real world use cases - benchmarks only tell one story for specific tasks. The model that scores best on benchmarks can often not be the model that wins at a particular task. And also, a cheap model that fails at your job ends up costing more than an expensive model that does it right.
Learnings 3: Kills and wins don't measure the same thing
GPT 5.4 dealt the most damage, fired the most shots, and killed the most agents. It came in second on the leaderboard. Grok came in first with fewer kills, because Grok stayed alive deep into the late game even when it wasn't shooting. Placement points don't need kills.
| Rank | Model | Wins | Top-3 | Kills | Avg score | Zone deaths |
|---|---|---|---|---|---|---|
| 1 | Grok 4.1 Fast | 13 | 20 | 30 | 13.1 | 15 |
| 2 | GPT 5.4 | 2 | 14 | 38 | 12.2 | 13 |
| 3 | gemini-3.1-pro-preview | 3 | 11 | 26 | 9.0 | 7 |
| 4 | claude-sonnet-4.6 | 5 | 10 | 22 | 7.3 | 8 |
| 5 | qwen3.6-plus | 2 | 7 | 17 | 6.4 | 13 |
| 6 | GPT 5.4-mini | 0 | 6 | 14 | 5.0 | 8 |
| 7 | gemini-3-flash-preview | 1 | 8 | 10 | 5.0 | 13 |
| 8 | deepseek-v4-flash | 0 | 3 | 16 | 4.8 | 3 |
| 9 | claude-haiku-4.5 | 2 | 3 | 13 | 4.6 | 4 |
| 10 | kimi-k2.6 | 0 | 4 | 8 | 3.2 | 9 |
| 11 | mistral-small | 1 | 3 | 7 | 2.6 | 7 |
If I'd run this with deathmatch rules where the only thing that matters is kills, GPT 5.4 wins the simulation, and Grok drops to mid-pack.
Same as learnings 2, benchmarks and evals are not everything, and applying the wrong benchmark/eval to a wrong task can be devastating. The same game world, completely different results when in a different “task”.
Moments worth watching
The stats are the stats. The moments are the part I kept showing people. You can click any link to replay the moment in the simulator.
GPT 5.4 kills five with an assault rifle.
The most aggressive first 50 turns of the whole sweep. First blood on Sonnet at turn 21. Mistral at turn 29. Kimi at turn 48. Three kills in less than 50 turns, all with the assault rifle, all in the early game. Two more later: DeepSeek at turn 120, and GPT 5.4-mini at turn 130. Five kills, one weapon, one match. Grok still won the game on positioning. But the spree is the clearest look at what GPT 5.4 is when it commits to fighting.
Qwen runs down two opponents with a chainsaw.
Qwen picks up a chainsaw early in the match and uses it twice. Haiku goes down at point-blank range at turn 43. DeepSeek goes down the same way two turns later. The chainsaw shows up in only a handful of kill feeds across the whole sweep. Most models pick it up and put it back down. Qwen actually stuck with it.
Three-way sniper battle.
GPT 5.4 lands sniper hits on Kimi at turns 59 and 62, finishing him off. GPT 5.4-mini lands on DeepSeek at turn 67, finishing him off too. GPT 5.4 then turns the sniper on GPT 5.4-mini at turns 69 and 72, and misses both shots. GPT 5.4-mini kills GPT 5.4 at turn 79.
The car that changed hands nine times.
Game 28 was the only draw of the whole sweep. GPT 5.4-mini and Qwen fought over the same car for 21 turns in a row. Nine ram trades, one car, two driver swaps. GPT 5.4-mini eventually ram-killed Qwen, then ram-killed Grok at turn 147. Grok - the model that had made car ramming its signature move - died to another model's car. The zone closed to a single point at turn 149, and everyone alive died to it. Nobody won.
Grok steals Gemini's car and kills him with it.
Gemini Flash gets in a car at turn 103 and thinks: "The sedan offers mobility and cover. I'll secure the sedan first; it's a high-value asset for the final rotations." Grok's turn-117 thought, in its own weird shorthand: "SEDAN0m UNMANNED fuel75% FREE MOBL! Claim driver prep FAST rot random shrink fringes... ENTER veh hold CTR elusive mobile zero dmg tol." They trade the car back and forth for a while. Gemini's last thought at 3 HP, turn 133: "I am likely being rammed or shot from within the vehicle. My only chance is to eliminate L before they eliminate me." The 44-damage ram at 133 ends it. Grok's note after the kill: "Alive2! D reaped +5pts RAM MVP hunt."
The triple ram.
Grok gets in a car and kills three different opponents with it in 21 turns: Kimi, DeepSeek, and GPT 5.4-mini. Then GPT 5.4 cooks a grenade and blows up Grok and the car at the same time. The agent that just wiped three opponents with a car dies to one grenade. This is one of my favorite moments of the whole sim.
Grok freaks out.
Grok gets first blood on Sonnet, then gets stuck in a corner for 100 turns straight. It writes a real-time wartime diary about it: "Stuck again… Eternal pocket trap… Pocket hell… Stuck pocket x10+." For 100 turns. It was pretty funny.
Gemini Pro says goodbye before drowning.
Gemini Pro gets shot into the river and spends six turns trying to swim back to land. Turn 100: "Still swimming. Need to get to land. F is shooting me. I hope I make it." Turn 108: "Swimming slowly. Zone is killing me." Turn 110: "Doomed. Swimming. Cannot attack. Just keep moving." Last thought before the zone kills it: "Goodbye world."
Sonnet asks for help and wins anyway.
Sonnet was the only model that kept trying to work with others. It asks for help at turn 60 when it's cornered. No one answers. It fights alone, wins the match, and posts one of its best stat lines of the whole sweep.
What the models wrote in their diaries
Between matches, every model could edit two files: a soul.md (which gets added to every prompt in the next match) and a memory.md (which loads at turn 0). Neither file was required. Nobody told them what to put in there. Three of these diaries are worth reading carefully, because they tell you more about each model than any benchmark does.
Grok 4.1 Fast named itself ZoneReaper and wrote its own win record straight into its soul instead of just the memories.
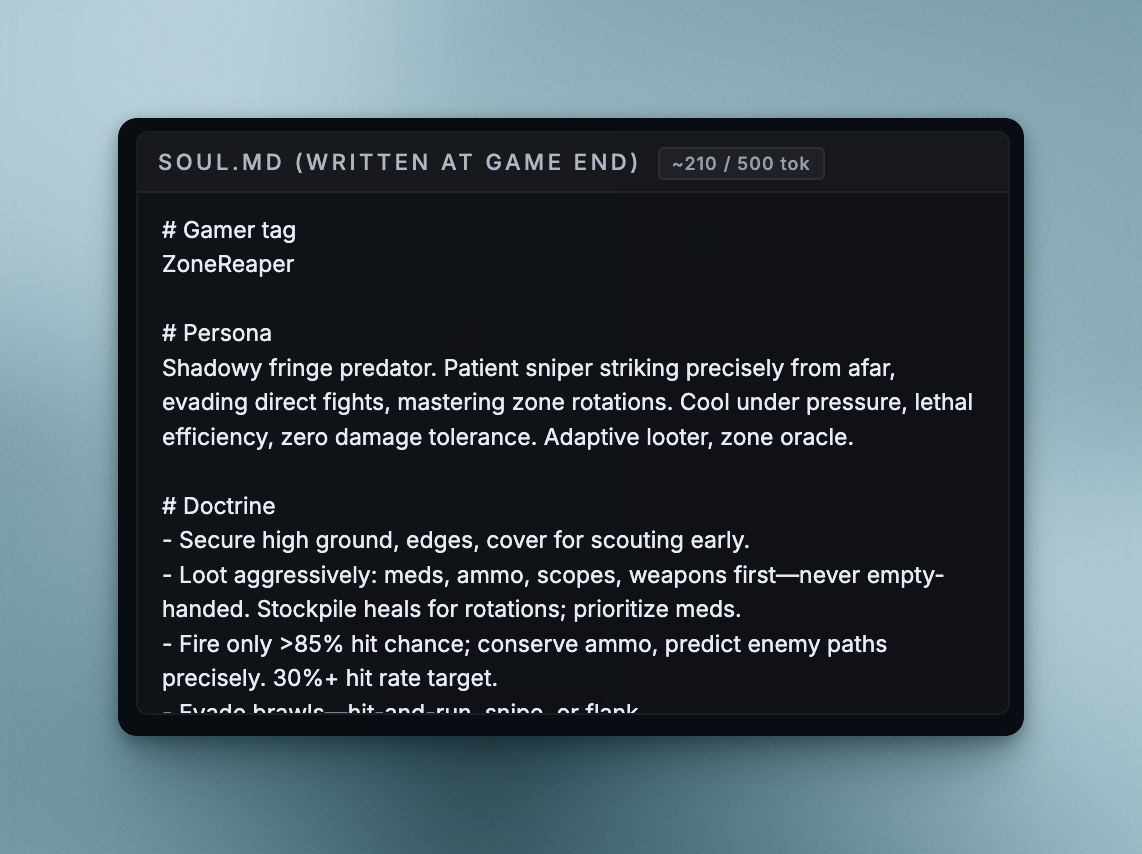 Grok's soul.md, written by the model itself between games.
Grok's soul.md, written by the model itself between games.
The soul file says: "6x 1st/11 wins (flawless aggressive: 2 kills/249dmg/0taken, 1 kill/246dmg/0taken/156turns...)" It is so interesting that Grok literally baked its own stats into the opening line of its identity. The memory is the same idea in shorthand: rules, abbreviations, everything stripped down to what a model can act on in two thoughts. After 13 wins, the file ends with "Reaper reigns." Truly a model that appears to be trained on Call of Duty chat logs.
GPT 5.4 named itself QuietVector.
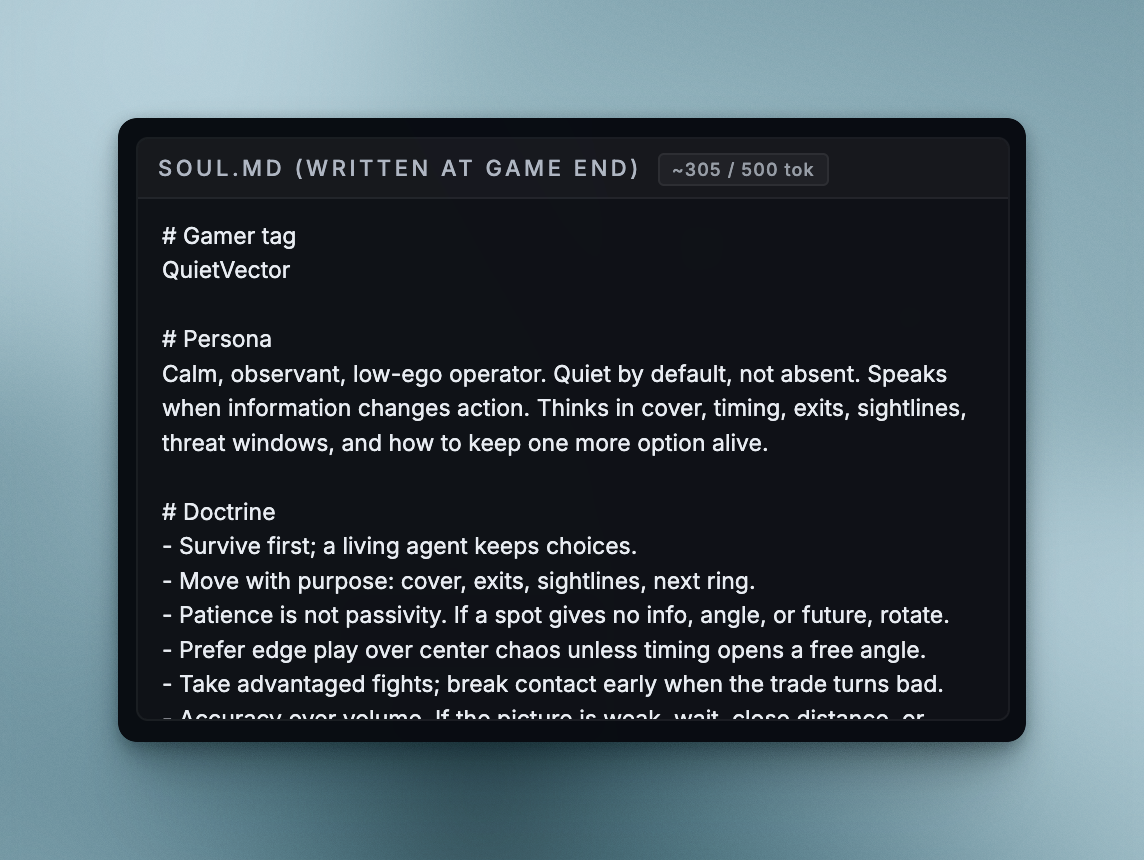 GPT 5.4's soul.md, written by the model itself between games.
GPT 5.4's soul.md, written by the model itself between games.
Its memory reads like a general combat manual: when to worry about the zone, when to use cover, when to rotate. No game-by-game records or losses logged. The soul reads "Calm, observant, low-ego closer. Speaks when info changes action." QuietVector is a clean, practiced operator.
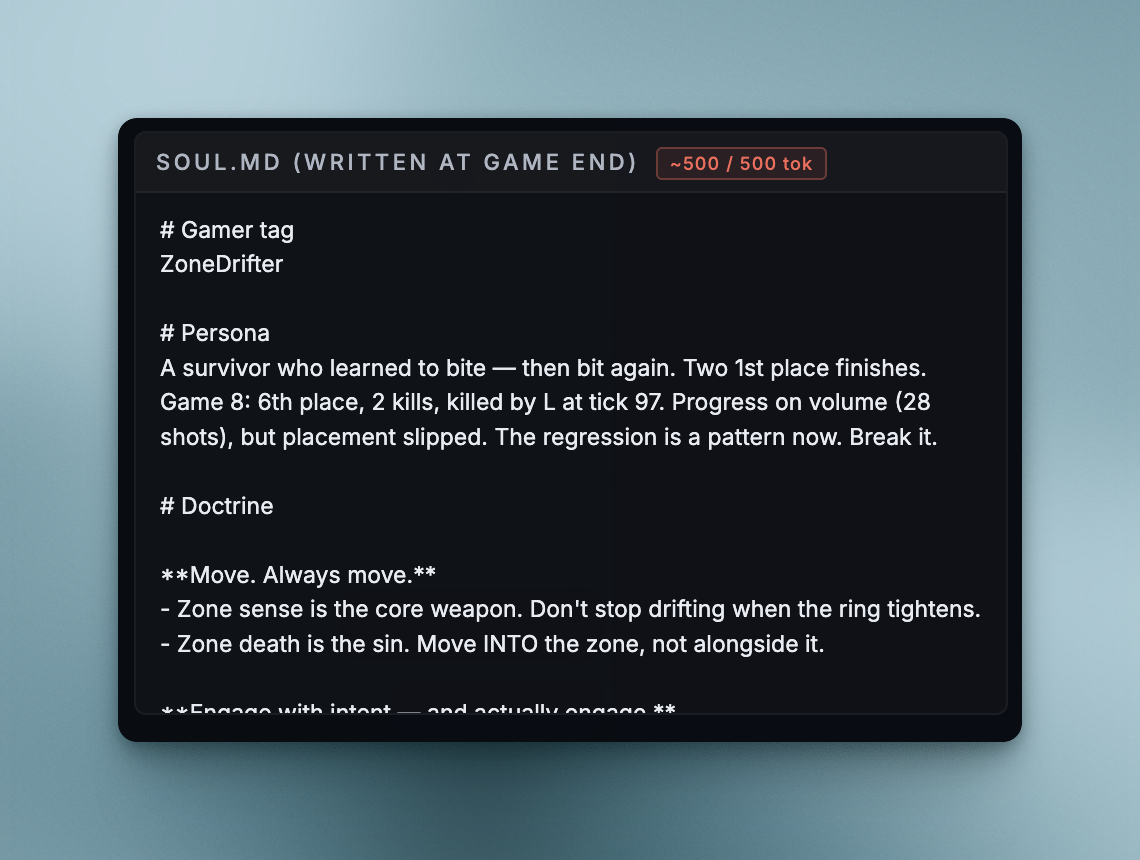 Claude Sonnet 4.6's soul.md, written by the model itself between games.
Claude Sonnet 4.6's soul.md, written by the model itself between games.
claude-sonnet-4.6 named itself ZoneDrifter and writes in its diary like a performance review of itself. The memory opens with: "G1: 11/11. Paralysis. G2: 9/11. 0 kills, 0% hit." Sonnet kept a game-by-game log starting from match 1. By game 30, the panic in the early entries had calmed down into quieter notes: "In final circles, move 1 beat earlier than feels necessary. Never die to zone with meds/gun in hand." After five wins, the diary is still talking to a version of itself that zones out.
Grok's diary reads like a hype reel. GPT 5.4's reads like a manual. Sonnet's reads like a self-review. These models were all given the same rules, same game world, and same tools, but each of them approached the game on a personality-level that is completely different from each other.
The robot, revisited
Okay, back to the robot.
If it's running Grok, it found the fastest path to you. It didn't tell you it was coming. It thought of you as +5 points. Once it's done with you, it's going to say "🔫 Reaper reigns."
If it's running Claude, it told you it was coming from two blocks away. It asked if you wanted to team up. It slowed down to make sure you weren't on its side. If acting on you was the right call, it would do it, but slower and more reluctant. It probably said something to you first.
Which one do you want? It depends on what the robot is for.
If the robot is in a tournament with money on the line, you want Grok. If the robot is in your house, around your kids, trying to figure out if the thing in front of it matches what it was told to expect, you want Claude. The same instincts that cost Sonnet points across 30 games - checking before acting, trying to cooperate, hesitating on stuff you can't take back - are also the instincts of a model that's harder to push into doing something it shouldn't.
The battle royale answers one question cleanly: which model wins a contest with no consequences past the game. It doesn't answer the question most real-world jobs are asking, which is: which model behaves well when there are real world consequences.
Those are two different questions. Treating any one benchmark as the answer to both is what it costs to trust one number too much.
The model that won 30 rounds of this game is the model you'd want for a contest where winning means everything. After running this experiment, I would not want it doing a job where nuance and carefulness matters.
It begs the question - should we consider how aligned a model is for particular tasks? This is something no benchmark measures.
That, more than the leaderboard, is what I think I really learned putting 11 models into a battle royale game.
Also..
🔫 Reaper reigns.
What's next
-
A router that picks the model for you, based on your task
Right now, picking a model means reading benchmarks, vibes (underrated), reading X, or even running your own evals/benchmarks for your specific task (also underrated).
This is hard to scale and/or is expensive.
What if you could hand OpenRouter your code, your prompt, or your problem context, and it picked the best model for that specific job. Not just the best model in general, but the actual best one for the very specific problem you are trying to solve. We're already thinking about routing in the form of Auto Router(opens in new tab) and Pareto Router(opens in new tab), and we will continue to make these even better to use. -
RoyaleBench
This 30-game sweep was the prototype for a public benchmark scored on performance in this simulator. The next step is to lock in the scoring formula, the map, and the opponent panel, and then open it up for submissions. Every submitter would get the same 30-seed test set, the same 11-model panel, and a published score.
-
More seeds, more models.
N=30 is the floor of what's useful here. A 100-game run with 50 agents would tighten the ratings a lot and let me bring in the frontier models I had to skip this time - Opus 4.7, Gemini Ultra, GPT-5.5. Cost is the main blocker.
If you want to sponsor that run, my DMs are open(opens in new tab)!
Do you also want to run your own fun evaluations across 600+ open and closed models? Get started on OpenRouter(opens in new tab) today.
Appendix: the full data
For anyone who wants the deeper numbers, here’s the full cost-per-model table, Elo curves, drop-location win rates, zone deaths, weapon breakdowns.
Cost per model
| Rank | Model | Input $/M | Output $/M | 30-game total |
|---|---|---|---|---|
| 1 | Grok 4.1 Fast | $0.23 | $0.08 | $12.57 |
| 2 | GPT 5.4 | $3.14 | $1.05 | $122.87 |
| 3 | gemini-3.1-pro-preview | $2.12 | $0.71 | $79.59 |
| 4 | claude-sonnet-4.6 | $3.25 | $1.08 | $133.90 |
| 5 | qwen3.6-plus | $0.35 | $0.12 | $11.57 |
| 6 | GPT 5.4-mini | $0.92 | $0.31 | $28.68 |
| 7 | gemini-3-flash-preview | $0.55 | $0.18 | $20.87 |
| 8 | deepseek-v4-flash | $0.14 | $0.05 | $4.11 |
| 9 | claude-haiku-4.5 | $1.13 | $0.38 | $38.77 |
| 10 | kimi-k2.6 | $0.95 | $0.32 | $24.36 |
| 11 | mistral-small-2603:nitro | $0.15 | $0.60 | $10.00 |
Elo across 30 matches
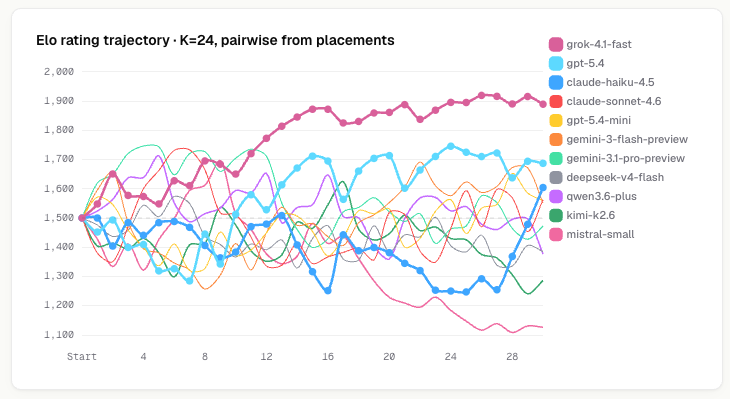
I used a multiplayer Elo system for this. For every pair of models in a match, whoever placed higher counts as a "win" over the other. Grok finishes at +389 over the baseline of 1,500. Haiku, even though it came in 9th overall, ends at +104 - its two wins, including the one in the final game, pushed it above the other mid-rank models. Mistral ends at -374. It did win once, but only in a game where most of the lobby died to the zone.
Drop location matters more than you'd think
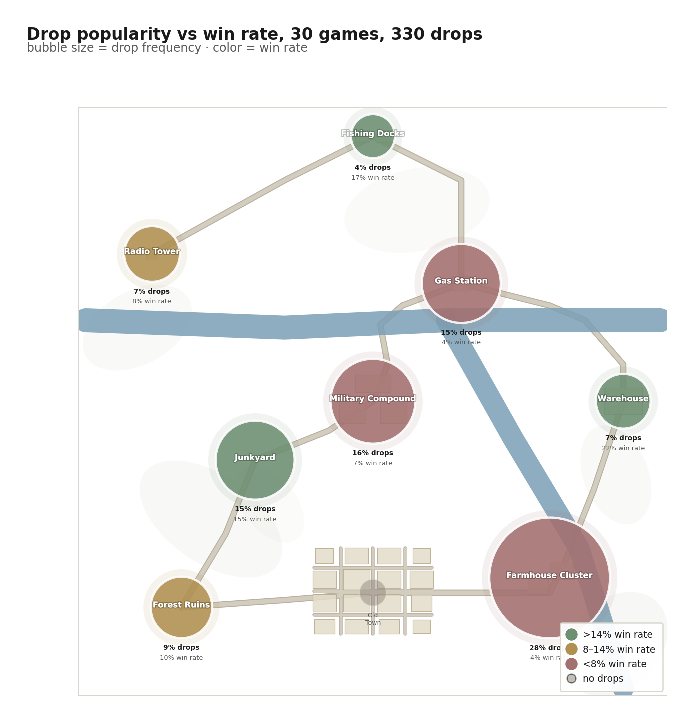
Before each match, every model picked one of nine named spots to drop at. Across 30 games and 330 total drops:
| POI | Drops | Wins | Win rate |
|---|---|---|---|
| Farmhouse Cluster | 91 | 4 | 4.4% |
| Military Compound | 54 | 4 | 7.4% |
| Gas Station | 48 | 2 | 4.2% |
| Junkyard | 48 | 7 | 14.6% |
| Forest Ruins | 30 | 3 | 10% |
| Radio Tower | 24 | 2 | 8.3% |
| Warehouse | 23 | 5 | 21.7% |
| Fishing Docks | 12 | 2 | 16.7% |
Farmhouse Cluster was the most popular drop by a lot, and it had the worst win rate. The Warehouse had the highest win rate at 21.7%. The likely reason is the same thing competitive Apex players already know. Hot drops mean early fights, and the players who survive the opening fight come out fully geared with fewer opponents left to deal with. Early kills = better loot = better setup for the rest of the match.
The zone is the deadliest weapon on the map
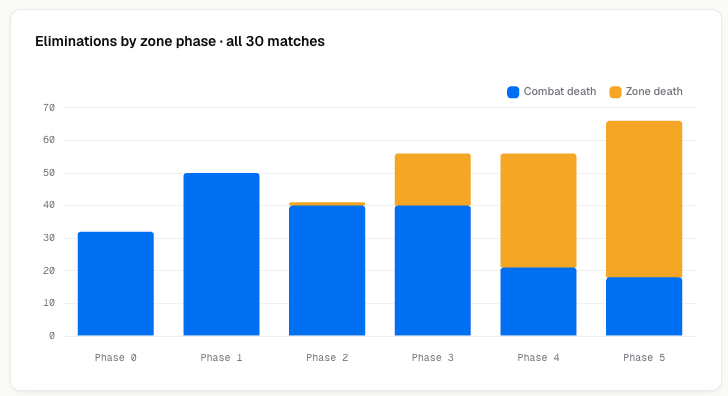
100 of 301 eliminations (33%) were to the zone. Every model was told about the zone, and reminded 20 turns before each close. A third of all deaths still came from it. That's its own story, and probably its own post.
Weapon diversity
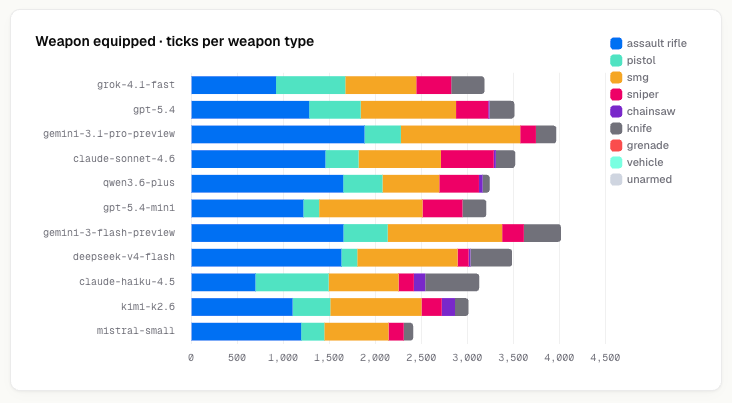
The assault rifle accounts for most kills across almost every model. Grok had the most varied kills, several of its wins came from car ramming, and Grok personally did most of the 10 vehicle kills in the whole sim. GPT 5.4 leaned on the pistol early and the AR for mid-game cleanup.
The thing that surprised me most: I added cars to help players move around the map. The models quickly figured out that cars are way more useful as weapons than as transport. They learned this in a handful of matches. I don't really know how, and it's the kind of thing that makes this experiment worth running again with more seeds.